목차
"문자 인식 및 번역" 대상 이미지 영역 선택하기
다음과 같이 일본어 이미지가 있는 화면에서 [새 캡처]를 누릅니다.
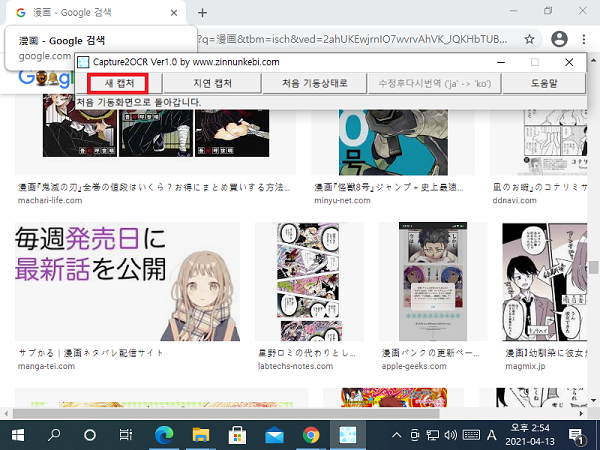
다음 화면과 같이 Capture2OCR툴이 최소화 되어 보이지 않게 되면서 현재 디스플레이 화면 전체가 약간 어둡게 변합니다. 어둡게 변한 화면이 문자 인식을 위해 영역을 지정할 수 있는 영역 지정 모드 입니다. 이 영역 지정 모드에서 문자로 뽑아내고 싶은 이미지의 왼쪽 상단을 마우스 왼쪽 버튼으로 누르고 오른쪽 하단으로 끌어서 버튼을 뗍니다. 선택한 대상은 빨간색 사각형으로 표시됩니다.
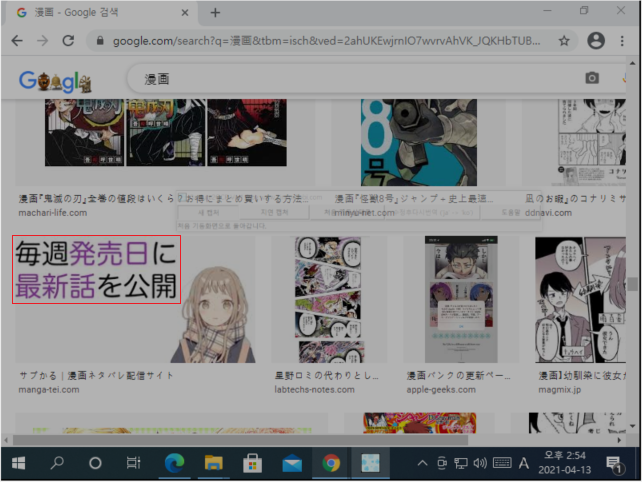
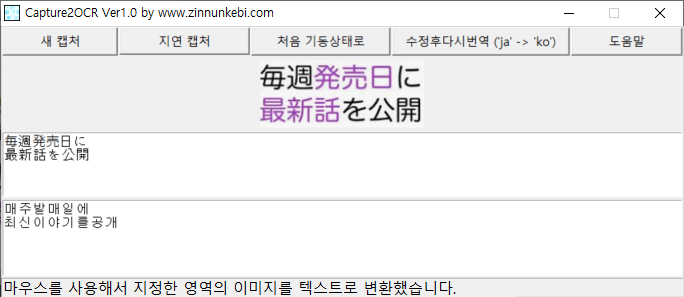
마우스로 영역 지정이 끝나자 마자 빨간색 사각형 범위의 이미지를 다음과 같이 Capture2OCR툴로 캡처 합니다. 그리고 이 캡처 이미지에서 일본어 문자를 뽑아내어 첫 번째 텍스트 영역에 표시합니다. 그리고 한글로 번역 하여 두 번째 텍스트 영역에 표시합니다.
이미지 영역 지정 취소하기
영역 지정 모드에서 캡처를 안 하고자 한다면 어둡게 변한 화면 위에서 마우스 오른쪽 버튼을 클릭 그리고 클릭을 떼고 Esc키를 누릅니다. 어두운 화면이 밝은 화면으로 바뀐다면 원래대로 돌아 간 것 입니다.
"지연 캡처"에 대해서
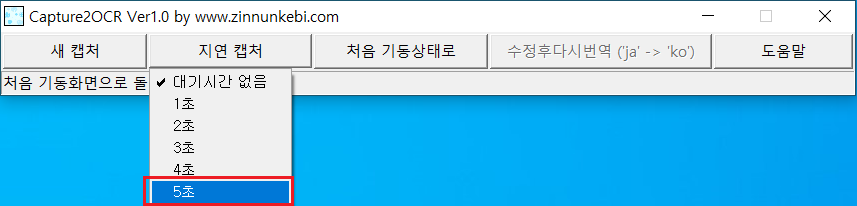
다음 화면과 같이 [지연 캡처] 버튼을 누르면 몇 초를 지연할 것인지 선택할 수 있는 “1초”부터 “5초”까지 리스트가 표시됩니다. 기본 설정은 "대기 시간 없음" 입니다. 예를 들어 “5초”를 선택해서 [새 캡처]를 누른다면 영역 지정 모드로 바뀔 때까지 “5초”를 기다립니다. 이 “5초”동안 캡처할 대상 화면을 변경할 수 있습니다. “5초”가 지나면 화면 전체가 약간 어둡게 변해 영역 지정 모드가 됩니다.
이미지에서 뽑아낼 대상 언어 및 번역 언어 선택하기
다음의 C:\cap2ocr\conf\cap2ocr_config.ini 파일을 수정하면 이미지에서 뽑아낼 대상 언어와 번역하고자 하는 언어를 선택할 수 있습니다.
기본 설정은 다음과 같습니다.ocr_tool_layout은6이 설정 되어 있고, ocr_lang=jpn만 나두고 나머지에 '#' 문자를 선두에 삽입해 주석 처리 하고 있습니다. 이것은 이미지 문자가 가로로 쓰여진 일본어인 경우의 설정입니다.
[CAP2OCR]
...중간 생략...
ocr_tool_layout=6
...중간 생략...
ocr_lang=jpn
#ocr_lang=jpn_vert
#ocr_lang=jpn+eng
...중간 생략...
그러나 다음 화면과 같이 세로로 나열된 일본어 이미지 문자에서 텍스트를 뽑아내고 싶다면 ocr_tool_layout=5로 변경, 그리고 ocr_lang=jpn_vert의 선두 '#'의 주석을 없애고 나머지에 '#' 문자를 선두에 삽입해 주석 처리 합니다.

[CAP2OCR]
...중간 생략...
ocr_tool_layout=5
...중간 생략...
ocr_lang=jpn_vert
...중간 생략...만약 일본어에 영어 알파벳이 섞여 있다면 일본어로 잘못 인식할 수 있습니다. 이것을 방지하는 방법으로 ocr_lang=jpn+eng를 사용합니다.
문자 인식 대상 언어는 다음 글의 Tesseract-OCR설치 과정에서 추가 언어 데이터를 선택해서 설치할 때 무엇을 설치 했는가 에 달려 있습니다. 예들 들어 추가 언어에 중국어를 선택 했다면 ocr_lang=chi_sim를 사용할 수 있습니다.


(주의 사항)설정 파일 cap2ocr_config.ini를 수정하여 수정 내용을 적용하려면 cap2ocr.exe를 재 기동 해야 합니다.
처음 기동 상태로 초기화하기
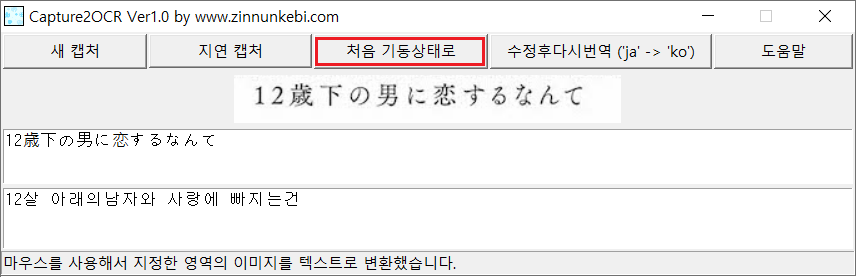
위와 같은 화면에서 [처음 기동상태로] 버튼을 누르면 다음과 같이 초기 기동 화면으로 돌아갑니다.

수정 후 다시 번역하기
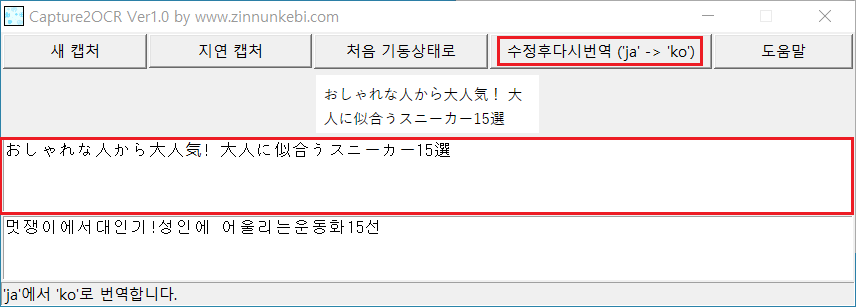
다음 화면의 일본어 "大人" 는 한글로 어른 또는 성인 입니다. 그러나 행 분할로 大와 人로 분리되어 "대 사람" 으로 번역 되었습니다.
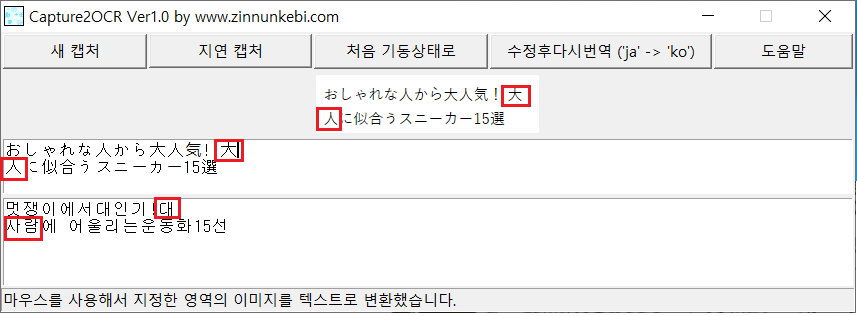
이미지는 수정할 수 없으므로 위 문제의 해결 방법으로 첫 번째 텍스트 영역은 수정이 가능합니다.
다음과 같이 분할 행을 없애고 [수정후다시번역('ja' -> 'ko')] 버튼을 클릭하면 조금 더 정확한 번역을 할 수 있습니다.